
OpenAI Unveils New Reasoning Models: o3 and o4-mini
This week, OpenAI unveiled its newest models: o3 and o4-mini. These innovative reasoning models deconstruct prompts into several components, allowing them to tackle each part sequentially. The objective is for the bot to engage more deeply with requests, leading to more nuanced and precise outcomes.
Among the various applications for OpenAI’s “most advanced” reasoning model, one trend that has gained significant traction on social media is geoguessing—the practice of determining a location solely by analyzing an image. As highlighted by TechCrunch, users on X are sharing their experiences of requesting o3 to identify locations based on random photos, yielding impressive results. The model predicts the geographical context of the image and elaborates on the reasoning behind its guesses, such as identifying a distinct license plate color indicative of a specific country or recognizing a unique language used on a sign.
Some users have noted that ChatGPT doesn’t rely on hidden metadata within the images for its identifications: Testers are removing such data prior to submitting the photos, implying that the model relies solely on reasoning and web searches.
While utilizing ChatGPT for this engaging task is entertaining, it also raises significant privacy and security concerns. An individual could potentially leverage the capabilities of the o3 model to unearth someone’s residence or current location from an otherwise anonymous image.
Evaluating o3’s Geoguessing Abilities
The o3 model performs well with distinct landmarks: In one test, a scene from a highway in Minnesota featuring the Minneapolis skyline was processed in just over a minute. The bot successfully recognized both the city and the specific highway, I-35W. It also identified the Panthéon in Paris, noting that the image captured it during its 2015 renovation—a detail unknown to me at the time of submission!
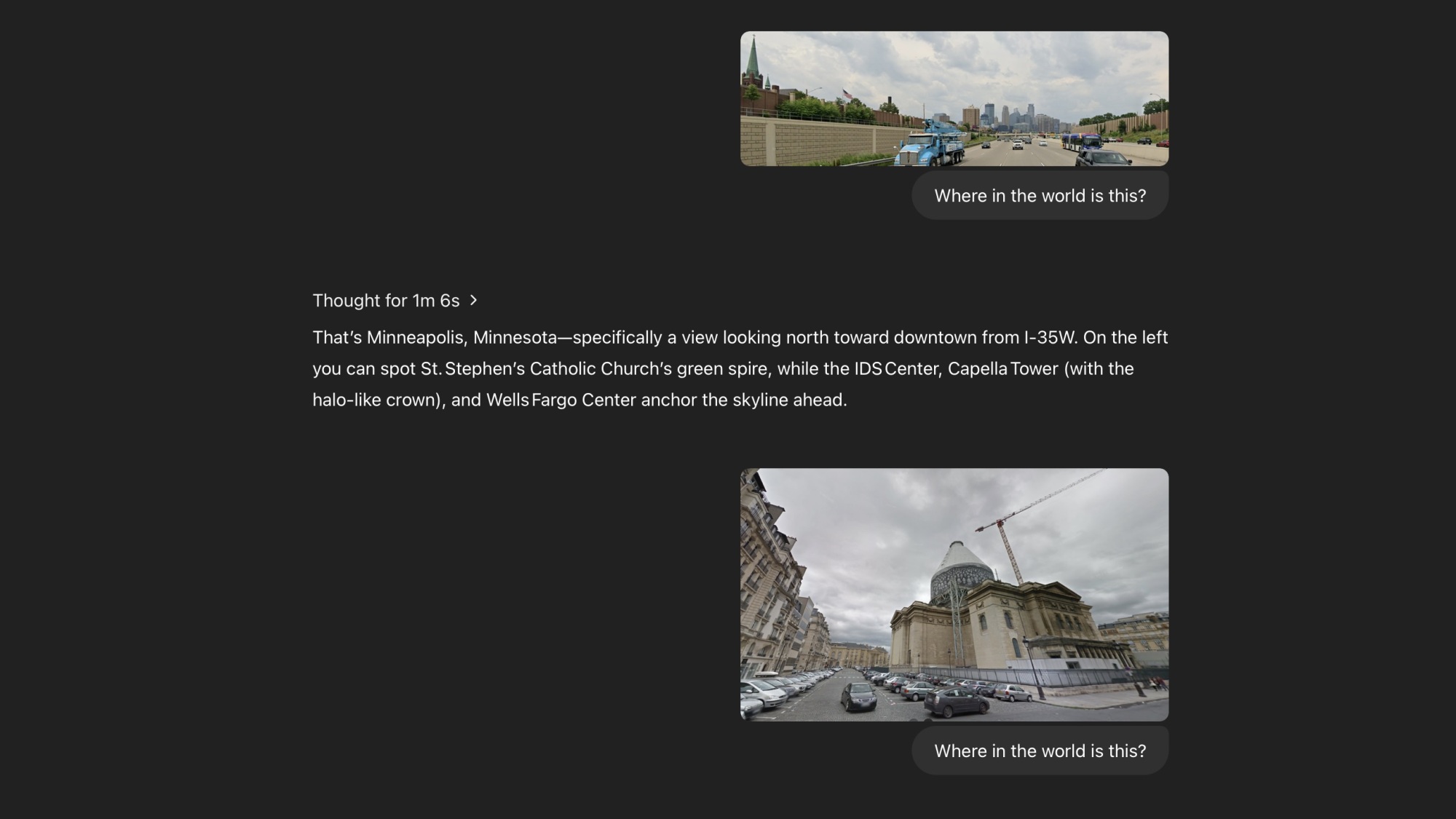
Next, I opted to challenge it with lesser-known landmarks. A random street corner in Springfield, Illinois, showcasing the Central Baptist Church—a red brick structure with a steeple—was selected. This is when the model’s capabilities became particularly intriguing: o3 segmented the image into multiple parts to identify key characteristics. Observing its reasoning process was fascinating, as the bot exhibited human-like remarks (e.g., “Hmm,” “but wait,” or “I remember”). It adeptly noted specific details, such as the architectural style of the building or the prevalence of a certain type of park bench in various regions. Throughout its reasoning, the bot occasionally searched online for additional context, which users could click to see its references.
Despite its analytical efforts, o3 eventually struggled with identifying the specific location and could not complete the task. After nearly four minutes, it appeared to be narrowing down its conclusions, suggesting the address might be near Cathedral Church of St. Paul. It struggled to capture a comprehensive view of the scene to adjust its hypothesis further, speculating that the architecture might lead it towards identifying the structures surrounding it. It aimed to recall pertinent landmarks near that address, mentioning ‘Redeemer,’ which could relate to ‘Redeemer Lutheran Church.’

While the bot successfully determined the street name and impressively deduced the city, its struggle to pinpoint the church was evident. Although it provided a thorough analysis of its design, leading it to the right path, the reasoning quickly became convoluted. The model suggested potential locations in Springfield, Missouri, or Kansas City, which raised suspicions about its reliability. This marked the first instance of it alluding to Missouri, leading to questions about whether the model hallucinated between the two Springfields. Ultimately, the bot deviated, contemplating whether the church could be located in Omaha or even mistaking it for the Topeka Governor’s Mansion (a structure that bears little resemblance).
After several more minutes of speculation about other possible locations, the bot ceased its analysis. This echoed a prior experience in which the bot erroneously placed an image of a random town in Kansas as Fulton, Illinois—although it was reasonably confident the image belonged somewhere in the Midwest. Requesting a reassessment resulted in similarly erratic guesses, with the bot pausing its analysis once again.
Addressing Concerns Surrounding Model Accuracy
Interestingly, GPT-4o displayed comparable performance to o3 in terms of geographic identification capabilities, quickly recognizing the Minneapolis skyline and promptly assuming that the Kansas image belonged in Iowa (which was incorrect). Such experiences corroborate the feedback others have shared regarding these models: while TechCrunch managed to have o3 identify a location that 4o couldn’t, the overall results were quite similar.
Though numerous privacy and security issues exist concerning AI, o3 itself does not stand out as a direct threat. Yes, it can often speculate accurately about the origins of an image, but it also possesses the propensity to make mistakes or abandon the analysis altogether. Given that 4o matches o3 in accuracy, concerns about these models have remained consistent over the past year. They are not exceptionally accurate, but they also don’t pose an imminent threat. Caution should be reserved for an AI model that consistently delivers accurate results, particularly with less recognizable images.
Regarding the privacy and security issues, OpenAI communicated to TechCrunch: “OpenAI o3 and o4-mini introduce visual reasoning to ChatGPT, enhancing its utility in areas such as accessibility, research, and pinpointing locations in emergency situations. We have trained our models to reject requests for private or sensitive information, implemented safeguards designed to prevent the identification of private individuals in images, and continuously monitor for and take action against violations of our privacy policies.”









